有限公司")





引言
随着互联网的快速发展,数据已经成为企业决策和用户需求的重要依据。实时数据对于许多应用场景至关重要,如股市行情、新闻资讯、在线购物等。将爬虫实时数据传输到前端,可以让用户第一时间获取最新信息,提高用户体验。本文将探讨如何实现爬虫实时数据到前端的传输,包括数据采集、处理和展示等环节。
数据采集
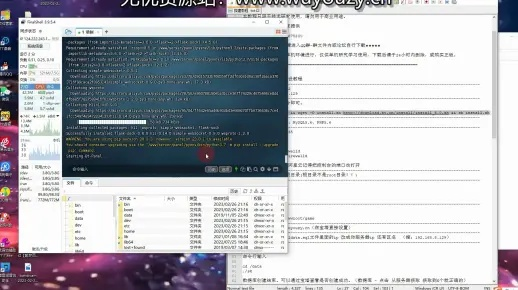
数据采集是爬虫实时数据传输的第一步。通常,我们使用爬虫技术从目标网站抓取数据。以下是一些常用的数据采集方法:
使用Python的requests库发送HTTP请求,获取网页内容。
利用BeautifulSoup或lxml等库解析HTML,提取所需数据。
使用Scrapy框架构建高效的数据采集流程。
在数据采集过程中,需要注意以下几点:
遵守目标网站的robots.txt规则,尊重网站版权。
合理设置爬虫的请求频率,避免对目标网站造成过大压力。
处理异常情况,如网络错误、数据格式错误等。
数据处理
采集到的数据通常需要进行处理,以便在前端展示。以下是一些数据处理步骤:
数据清洗:去除无效数据、重复数据、异常数据等。
数据转换:将数据转换为前端所需的格式,如JSON、XML等。

数据存储:将处理后的数据存储到数据库或缓存中,以便后续使用。
在数据处理过程中,需要注意以下几点:
保证数据的一致性和准确性。
优化数据处理速度,提高系统性能。
考虑数据的安全性,防止数据泄露。
数据传输
处理后的数据需要传输到前端。以下是一些常用的数据传输方式:
WebSocket:实时双向通信,适用于需要实时数据传输的场景。
轮询:前端定时向服务器发送请求,获取最新数据。
长轮询:前端发送请求后,服务器保持连接,直到有新数据时才返回。
Server-Sent Events(SSE):服务器主动推送数据到前端。
在选择数据传输方式时,需要考虑以下因素:
实时性要求:WebSocket和SSE适用于实时性要求较高的场景。
系统资源:轮询和长轮询对系统资源消耗较小。
开发难度:WebSocket和SSE的开发难度相对较高。
前端展示
数据传输到前端后,需要进行展示。以下是一些常用的前端展示方法:
使用JavaScript动态更新页面内容。
使用前端框架(如React、Vue等)构建动态页面。
使用图表库(如ECharts、Highcharts等)展示数据。
在展示数据时,需要注意以下几点:
界面美观、易用。
数据展示清晰、直观。
响应速度快,减少用户等待时间。
总结
爬虫实时数据到前端的传输是一个复杂的过程,涉及数据采集、处理、传输和展示等多个环节。通过合理选择技术方案,优化系统性能,可以提高用户体验,为企业带来更多价值。本文从数据采集、处理、传输和展示等方面进行了探讨,希望能为相关开发者提供一些参考。
转载请注明来自互诺实验设备(衡水)有限公司,本文标题:《爬虫实时数据到前端,爬虫 数据 》



 冀ICP备2024085275号-1
冀ICP备2024085275号-1