有限公司")





引言
排序是计算机科学中的一项基本操作,几乎所有的数据处理任务都需要对数据进行排序。高效的排序算法对于提高程序性能至关重要。本文将探讨几种常见的排序高效算法,并分析它们的原理和适用场景。
冒泡排序
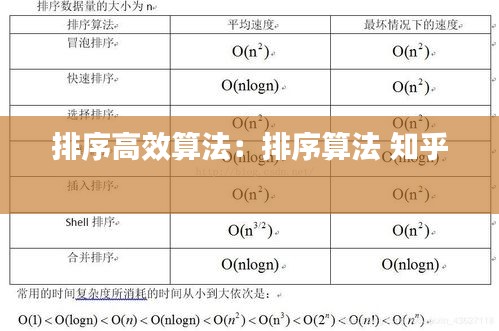
冒泡排序是一种简单的排序算法,它重复地遍历待排序的列表,比较每对相邻的项目,如果它们的顺序错误就把它们交换过来。遍历列表的工作是重复进行的,直到没有再需要交换的元素为止。冒泡排序的时间复杂度为O(n^2),适用于小规模数据的排序。
选择排序
选择排序是一种简单直观的排序算法。它的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。选择排序的时间复杂度也是O(n^2),适用于数据量较小的场景。
插入排序
插入排序是一种简单直观的排序算法。它的工作原理是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。插入排序的时间复杂度为O(n^2),但它在某些特定情况下(如部分已排序的数据)可以达到O(n)的时间复杂度。
快速排序
快速排序是一种效率较高的排序算法,由东尼·霍尔提出。它采用分而治之的策略,将原始数组分成较小的两个子数组,然后递归地对这两个子数组进行排序。快速排序的平均时间复杂度为O(n log n),在大多数实际情况下都优于其他O(n log n)算法。快速排序的关键在于选择一个合适的“基准”元素,以及如何将数组划分为两个子数组。
归并排序
归并排序是一种分治法排序算法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。归并排序的时间复杂度为O(n log n),它是一种稳定的排序算法,适用于大规模数据的排序。归并排序需要额外的存储空间来合并子序列,因此它的空间复杂度为O(n)。
堆排序
堆排序是一种基于比较的排序算法。它利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序的平均时间复杂度为O(n log n),但它是一种不稳定的排序算法。堆排序在空间复杂度上优于归并排序,为O(1)。

总结
排序算法的选择对于程序的性能有着重要的影响。本文介绍了冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序这几种常见的排序算法,并分析了它们的原理和适用场景。在实际应用中,应根据具体需求选择合适的排序算法,以达到最佳的性能效果。
转载请注明来自互诺实验设备(衡水)有限公司,本文标题:《排序高效算法:排序算法 知乎 》





 冀ICP备2024085275号-1
冀ICP备2024085275号-1
还没有评论,来说两句吧...