有限公司")





引言
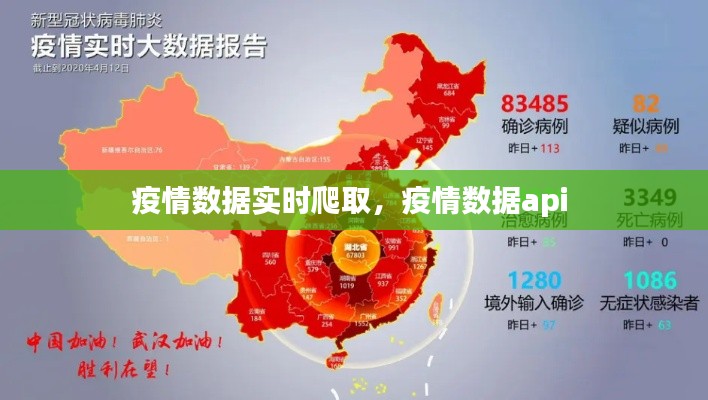
随着全球疫情的不断发展和变化,实时获取疫情数据对于政府决策、公共卫生管理和公众知情都非常重要。疫情数据的实时爬取成为了数据科学家和开发者的一个重要任务。本文将探讨疫情数据实时爬取的方法、挑战以及在实际应用中的重要性。
疫情数据的重要性
疫情数据包括确诊病例数、死亡病例数、治愈病例数、疑似病例数等关键指标。这些数据可以帮助我们了解疫情的传播速度、趋势和分布情况。实时爬取这些数据可以让我们及时响应疫情变化,采取有效的防控措施。
疫情数据实时爬取的方法
疫情数据的实时爬取通常涉及以下几个步骤:
数据源选择:首先需要确定数据源,这可以是政府官方网站、世界卫生组织(WHO)等权威机构发布的数据。
数据解析:使用爬虫技术解析网页内容,提取所需的数据。常用的解析方法包括正则表达式、XPath、BeautifulSoup等。
数据存储:将爬取到的数据存储到数据库中,以便进行后续的数据分析和处理。
数据清洗:对爬取到的数据进行清洗,去除重复、错误或不完整的数据。
数据可视化:将清洗后的数据通过图表等形式进行可视化展示,以便更直观地了解疫情情况。
爬虫技术概述
爬虫技术是自动化获取网页内容的一种方法。常见的爬虫技术包括:
网络爬虫:通过模拟浏览器行为,自动访问网页并提取数据。
深度爬虫:不仅爬取网页内容,还爬取网页中链接指向的其他页面。
分布式爬虫:通过多台服务器同时进行爬取,提高爬取效率。
在选择爬虫技术时,需要考虑数据源的特点、爬取速度、数据量等因素。
挑战与应对策略
疫情数据实时爬取面临着一些挑战,主要包括:
数据源变化:疫情数据更新频繁,数据源的结构和格式可能随时发生变化,需要及时调整爬虫策略。
反爬虫机制:一些数据源为了保护数据安全,会采取反爬虫措施,如IP封禁、验证码等,需要采取相应的应对策略。
数据质量:爬取到的数据可能存在错误或不完整,需要进行数据清洗和验证。
针对这些挑战,可以采取以下应对策略:
动态调整爬虫策略:根据数据源的变化及时调整爬虫规则,确保数据获取的准确性。
使用代理IP:通过使用代理IP,可以避免被数据源封禁。
验证码识别:使用OCR技术或其他验证码识别工具,自动识别和解决验证码问题。
数据质量监控:建立数据质量监控系统,及时发现并处理数据错误。
实际应用与效果
疫情数据实时爬取在实际应用中取得了显著的效果。例如,一些开发者和研究机构通过爬取疫情数据,制作了疫情地图、趋势分析报告等,为政府决策和公众提供了重要参考。此外,实时爬取的疫情数据还可以用于以下方面:
疫情风险评估:根据疫情数据,评估不同地区、不同人群的疫情风险,制定相应的防控措施。
公共卫生监测:实时监测疫情变化,及时发现潜在的疫情爆发点。
公众知情:向公众提供权威、准确的疫情信息,增强公众的防控意识。
结论
疫情数据实时爬取是应对疫情挑战的重要手段。通过有效的爬虫技术和应对策略,可以实时获取疫情数据,为政府决策、公共卫生管理和公众知情提供有力支持。随着技术的不断进步,疫情数据实时爬取将在未来发挥更加重要的作用。
转载请注明来自互诺实验设备(衡水)有限公司,本文标题:《疫情数据实时爬取,疫情数据api 》







 冀ICP备2024085275号-1
冀ICP备2024085275号-1