有限公司")





在当今大数据的时代,数据的处理和分析成为了许多企业和组织的核心需求,SparkSQL作为Apache Spark生态系统中的重要组成部分,以其处理速度高效的特点受到了广泛的关注和应用,本文将深入探讨SparkSQL处理速度高效的背后原因。
SparkSQL简介
SparkSQL是Apache Spark中的模块之一,为结构化数据提供了一个SQL接口,它允许用户使用SQL语句进行数据的查询、分析和处理,与传统的数据库查询语言相比,SparkSQL在处理大数据时表现出更高的效率和灵活性。
处理速度高效的原因
1、内存管理优化:SparkSQL采用了Spark的内存管理机制,能够高效地利用内存资源,在处理大数据时,数据被存储在内存中,避免了频繁的磁盘读写操作,从而大大提高了数据处理速度。
2、向量化执行引擎:SparkSQL的向量化执行引擎能够大幅度提升数据处理的性能,向量化执行意味着一次处理多个数据项,减少了每次处理数据时的开销,从而提高了处理速度。
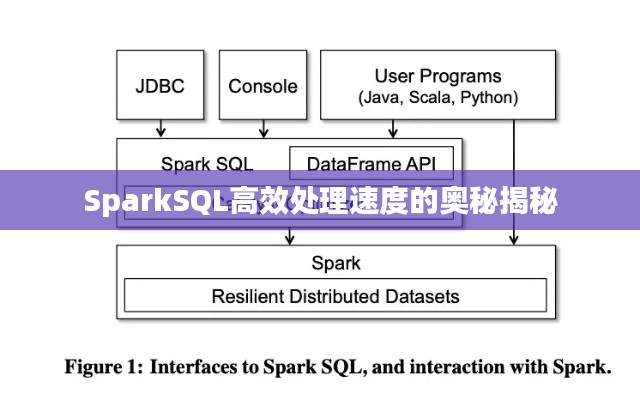
3、SQL与Spark生态系统的集成:SparkSQL与Spark生态系统的其他组件(如Spark MLlib、GraphX等)无缝集成,使得在处理数据时能够充分利用Spark的分布式计算能力,从而提高了处理速度。
4、灵活的查询优化:SparkSQL提供了灵活的查询优化功能,能够根据数据的特性和查询的需求进行智能优化,这使得在处理复杂查询时,SparkSQL能够快速地返回结果。
5、支持多种数据源:SparkSQL支持多种数据源,包括CSV、JSON、Parquet等,这使得在处理不同格式的数据时,无需进行数据格式的转换,从而提高了处理速度。
如何提高SparkSQL处理速度
1、优化数据分区:合理设置数据分区可以提高数据的并行处理能力,从而提高SparkSQL的处理速度。
2、使用广播变量:在查询中使用广播变量可以减少数据的传输开销,提高查询速度。
3、避免使用复杂的JOIN操作:复杂的JOIN操作可能会导致查询性能下降,可以通过优化数据结构或查询逻辑来避免使用复杂的JOIN操作。
4、使用合适的缓存策略:合理地使用缓存策略可以避免重复计算,提高查询速度。
SparkSQL以其处理速度高效的特点在大数据处理领域得到了广泛应用,其高效的内存管理、向量化执行引擎、与Spark生态系统的集成以及灵活的查询优化等功能使得它在处理大数据时表现出色,通过优化数据分区、使用广播变量、避免复杂JOIN操作以及使用合适的缓存策略等方法,可以进一步提高SparkSQL的处理速度,随着技术的不断发展,相信SparkSQL将在大数据处理领域发挥更大的作用。
转载请注明来自互诺实验设备(衡水)有限公司,本文标题:《SparkSQL高效处理速度的奥秘揭秘》





 冀ICP备2024085275号-1
冀ICP备2024085275号-1
还没有评论,来说两句吧...